How Machine Learning Algorithms Can Dramatically Improve your Estimation Predictions
At QSM, we have been on the leading edge of software estimation technology for 40 years. One of our recent innovations is to incorporate machine learning into our SLIM-Suite of estimation and measurement tools. If you are not familiar, the whole concept of machine learning is to “train” your algorithms with data to improve the accuracy of their predictions. Simple in concept, but the devil is in the details. In software project estimation, we are always asked to provide timely decision-making predictions based on skimpy information. Depending on the situation, our analysis will typically focus on one or several of the following criteria:
- Schedule (Time to market)
- Effort (Cost to develop)
- Staffing and Resources Required
- Required Reliability at Delivery
- Minimum-Maximum Capability or Functionality Tradeoffs
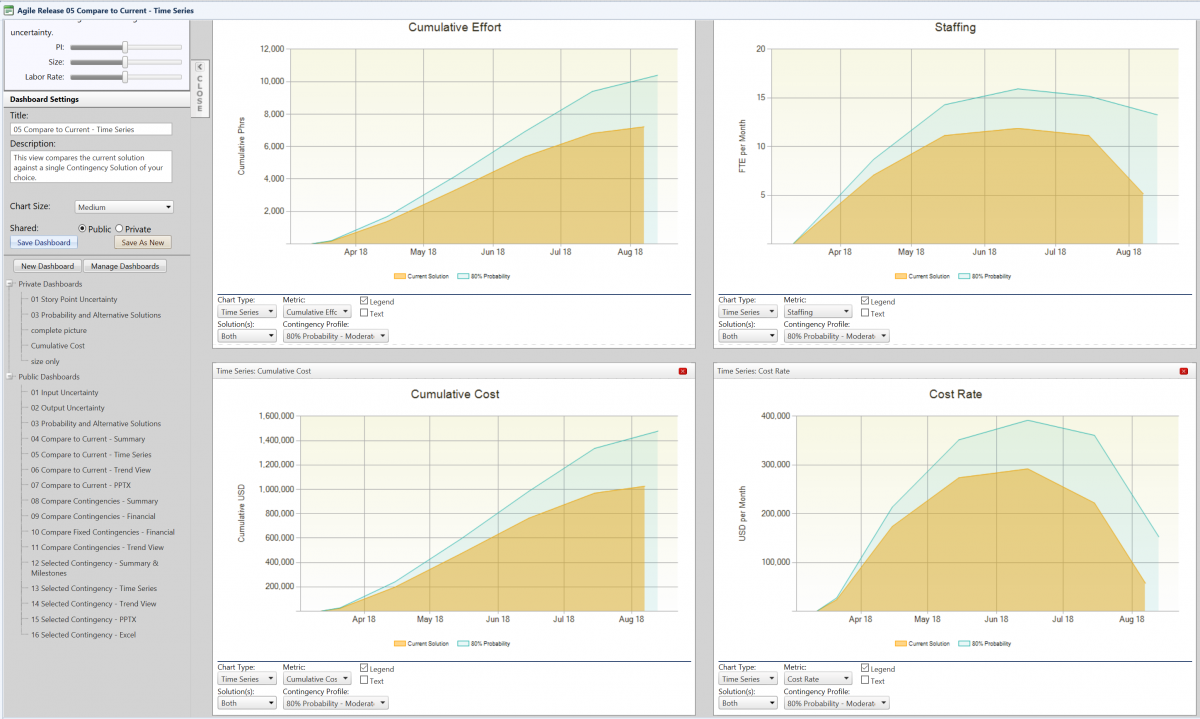
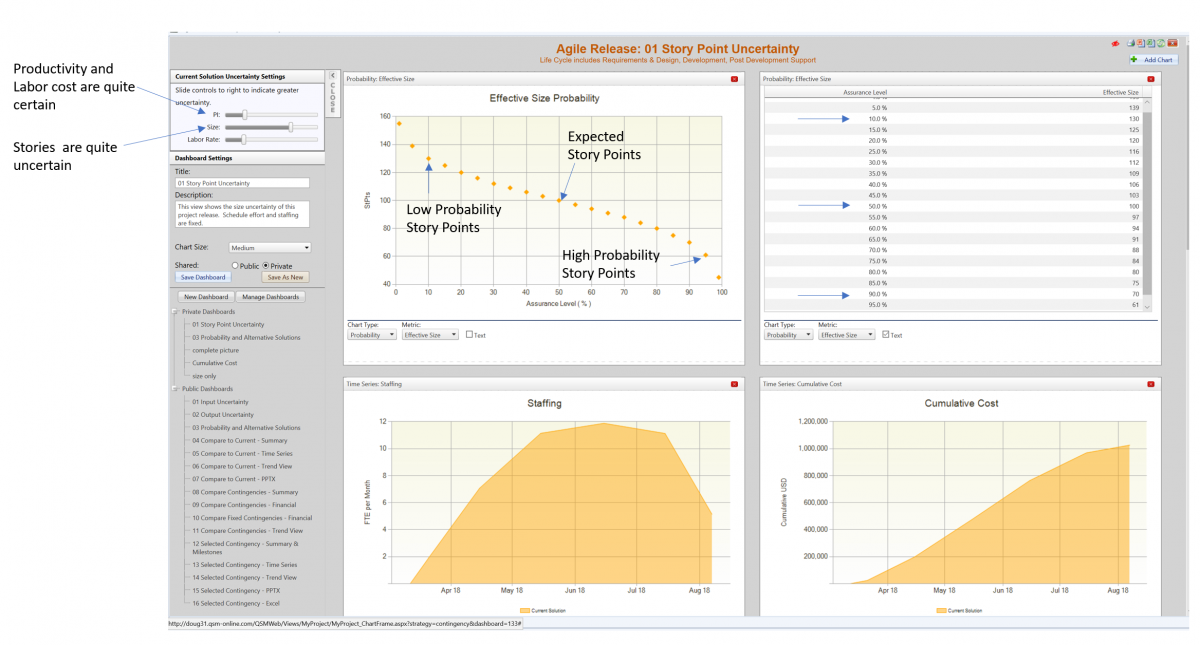
We start the training process by utilizing data from completed projects using these five core metrics. The data usually resides in tools like Jira or PPM products. Once obtained, we run statistical analysis on the data to determine typical behaviors and variability.
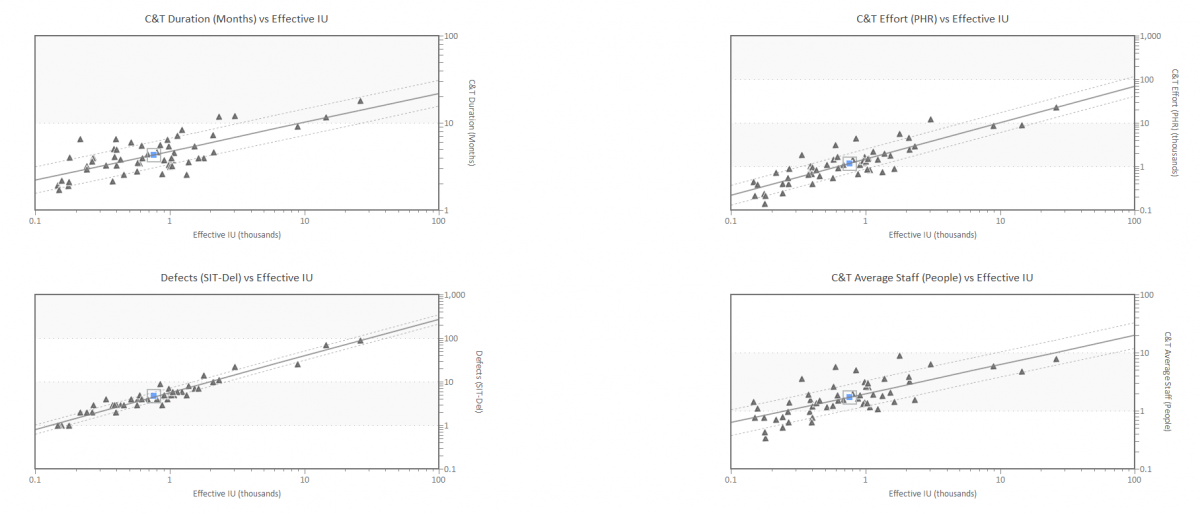
Figure 1. Project data used in SLIM Machine Learning Training Process. Triangles represent completed projects. Lines are curve fits of the average behavior and statistical variation in the positive and negative directions. These charts show how time, effort and staffing change depending on the size of the product to be developed.